Mysql 实现读写分离
本文最后更新于:2023年7月11日 晚上
如果我们只有一台数据库,那我们所有的读写请求都会压到这台数据库上。我们可以通过配置主从数据库来缓解数据库压力,将读操作和写操作分散到不同的数据库上。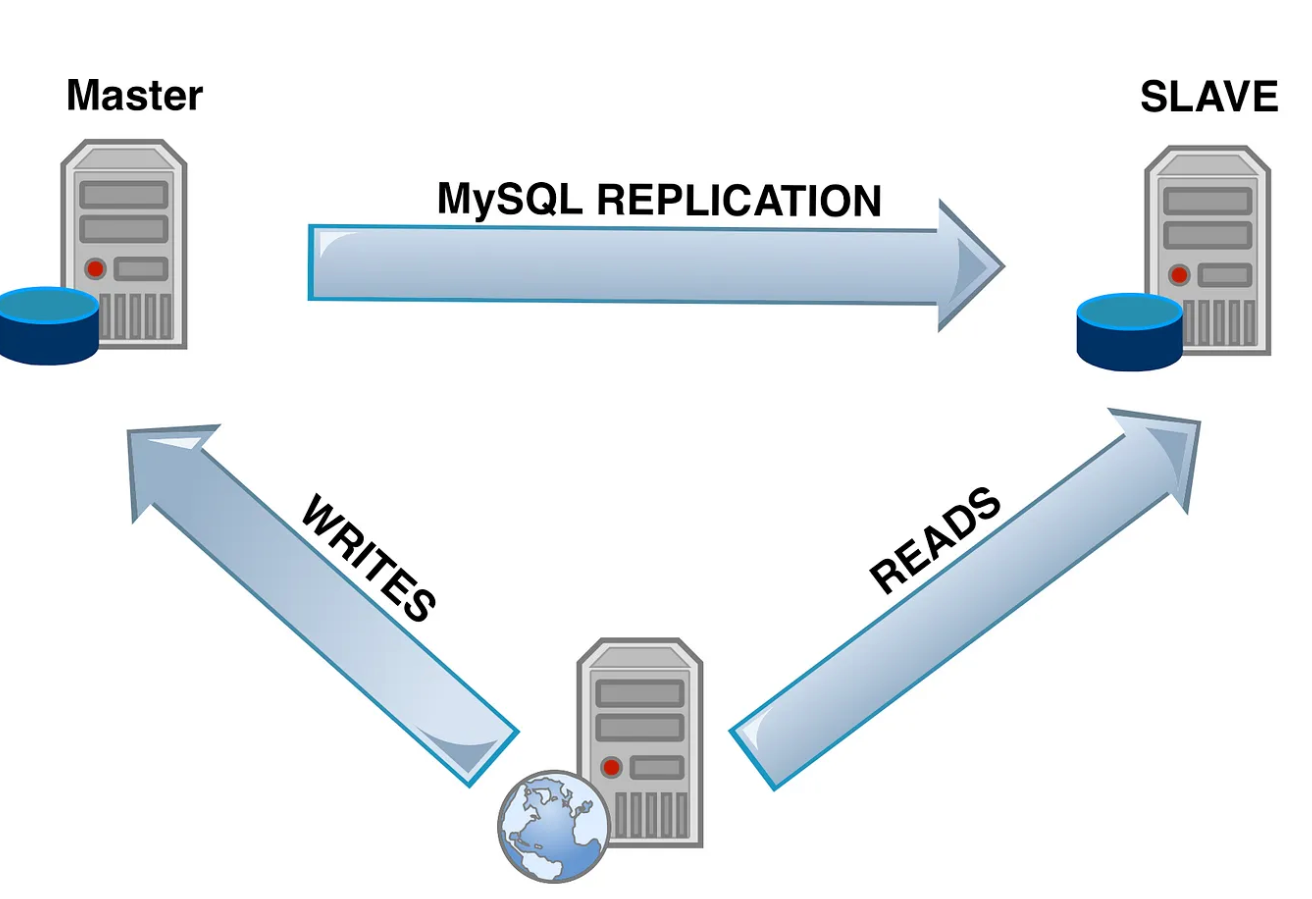
读写分离需要借助 Mysql 的主从复制机制进行实现。如果我们有多台服务器,我们就可以选择一台服务器作为主数据库,其余的则作为从数据库。所有的写操作都在主数据库完成,而读操作在从数据库上完成。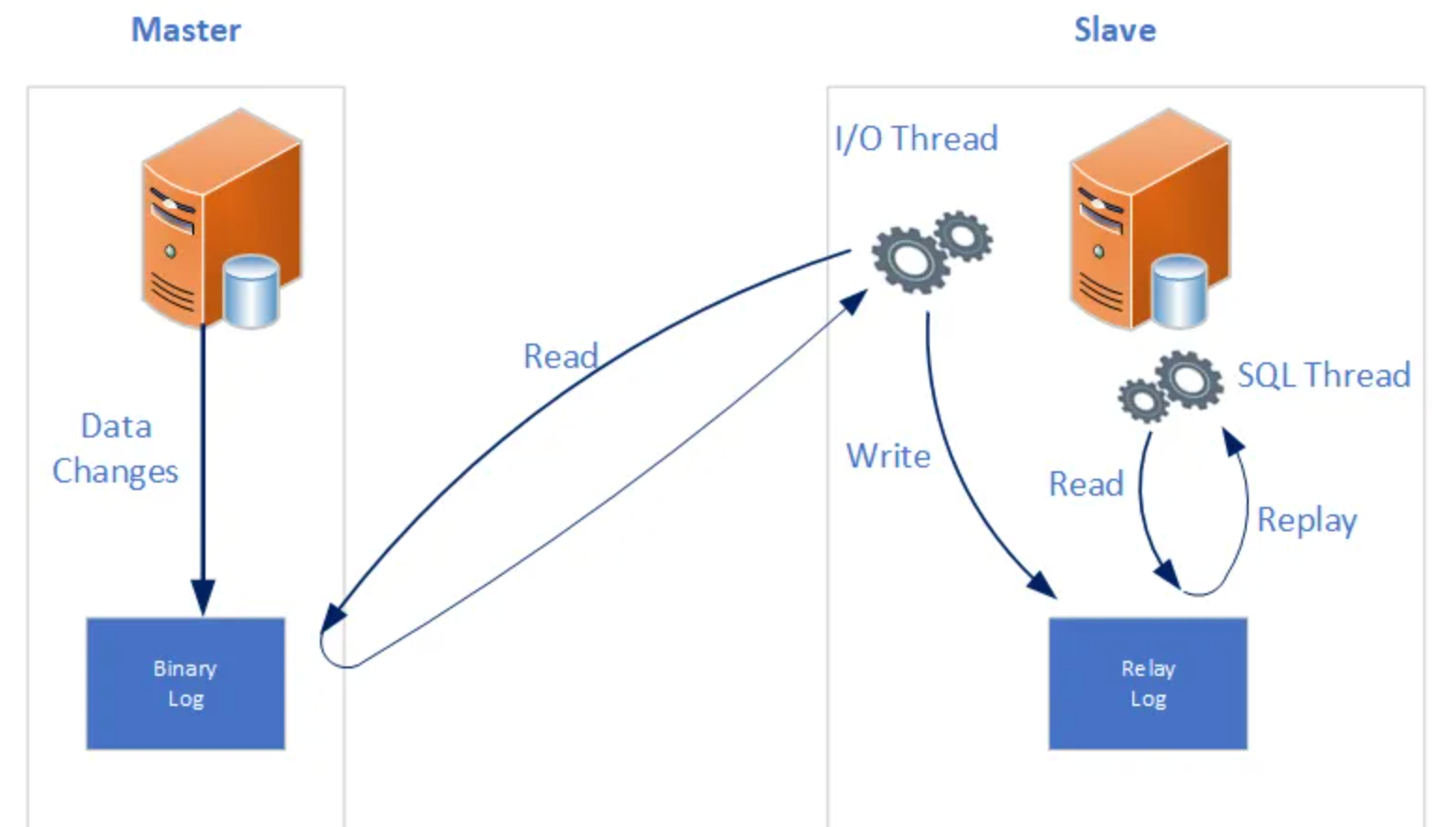
Slave 先读取 Master 的二进制操作日志,然后自己再重新执行一边 Master 的操作,从而实现主从复制。
Mysql 读写分离
操作系统:CentOS 7
数据库版本:Mysql 5.7
在配置主从数据库前,我们得有两台服务器才行,所以我们先复制一台虚拟机出来。需要注意的是,VMware 复制虚拟机之后,这两台虚拟机的所有配置都是一样的,ip 地址,网卡 mac,uuid。所以复制完成虚拟机之后,我们先打开其中一台,为它分配新的 ip、mac、uuid。
1. 虚拟机配置
- 先使用
uuidgen命令生成一个新的 uuid,然后复制一下 vim /etc/sysconfig/network-scripts/ifcfg-ens33修改静态 ip、uuid、最后再新增一个 HDARRD 配置,值可以在vmware -> 虚拟机 -> 设置 -> 网络适配器 -> 高级 -> MAC 地址中找到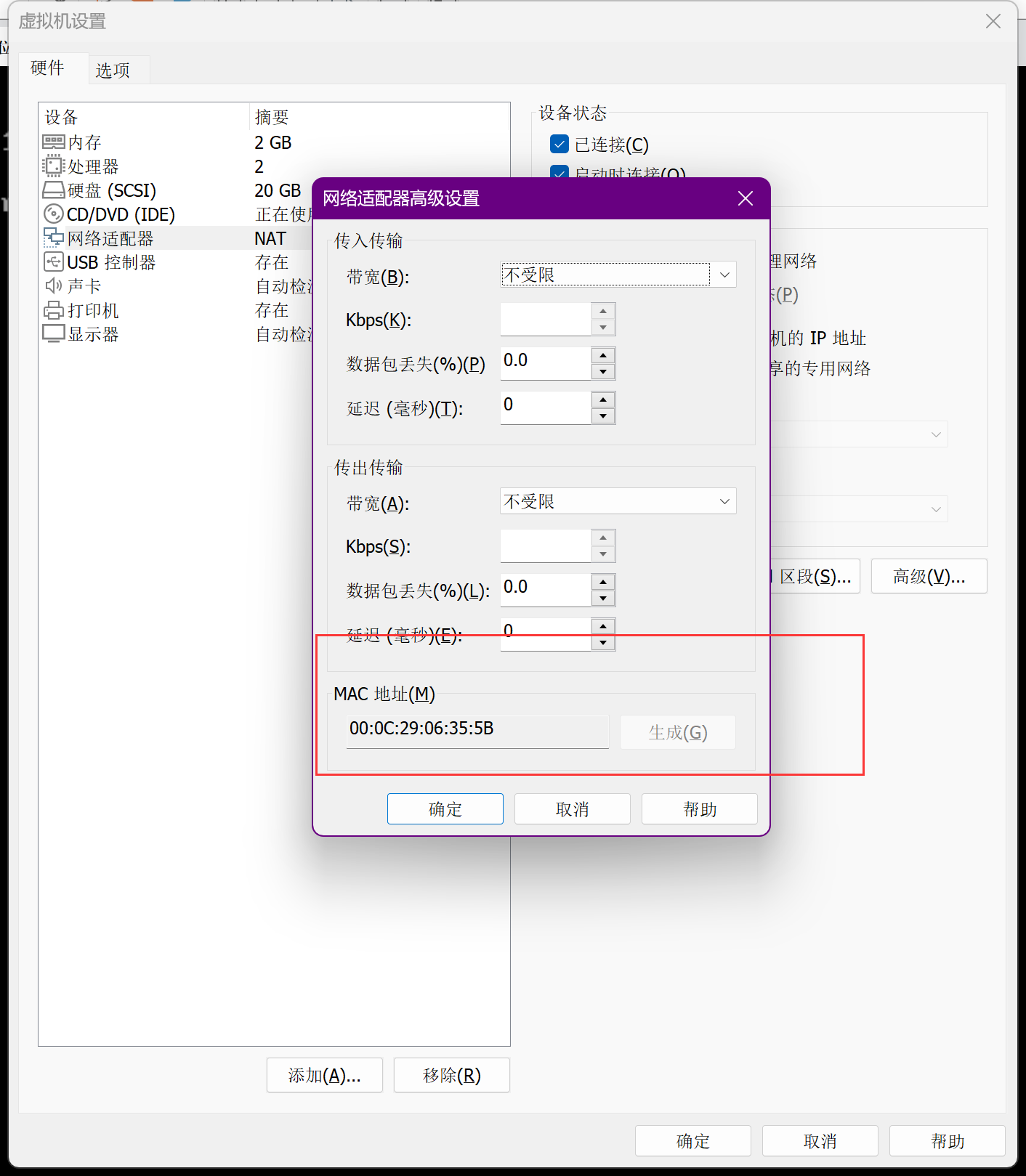
- 配置完保存之后,
service network restart重启网络服务,然后用 shell 重新连接到子服务器。
2. Mysql 配置
因为最开始我们是直接复制的虚拟机,所以两台服务器中 Mysql 的 uuid 是相同的,我们需要修改一下,否则待会是无法连接的。
- Slave 进入 Mysql,使用
select uuid()生成一个 uuid1
2
3
4
5
6
7mysql> select uuid();
+--------------------------------------+
| uuid() |
+--------------------------------------+
| 5c1b56b8-1fd4-11ee-b94b-000c29c57f1a |
+--------------------------------------+
1 row in set (0.00 sec) - 复制这个 uuid,修改
/var/lib/mysql/auto.cnf,将我们刚刚复制的 uuid 粘贴进去1
2[auto]
server-uuid=6f1a4b2a-1f98-11ee-a950-000c29c57f1a - 最后重启 Mysql 服务
service mysqld restart
2.1 主库配置
现在,我们进行主从配置,先配置主数据库
- 修改 Mysql 的配置文件
/etc/my.cnf,启用二进制日志系统,并分配服务器 id然后重启 MySQL 服务1
2
3
4
5[root@localhost src]# vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin # enable binary log
server-id=100 # enable server idsystemctl restart mysql。 - 登录到主数据库,创建一个用户给 Slave 使用
GRANT REPLICATION SLAVE ON *.* to 'slaveuser'@'%' identified by 'Root@123456';(如果是 Mysql 8 及以上的版本需要先创建用户再授权)。 - 调出主数据库的状态信息,查看日志状态,记住这里的 File 和 Position 属性。之后不要再对主数据库做任何操作,否则日志状态会发生改变。之后切换到子服务器,对 Slave 进行配置。
1
2
3
4
5
6mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 75757 | | | |
+------------------+----------+--------------+------------------+-------------------+
2.2 从库配置
- 和 Master 第一步配置类似,我们只需要为从库分配一个 server-id 就可以了,不需要启用它的二进制日志。分配后重启 MySQL 服务。
- 登录进 Slave 的 MySQL,执行下面的 Sql 为其添加一个 Master。
1
2
3change master to
master_host='192.168.19.100', master_user='slaveuser', master_password=' Roct@123456 ',
master_log_file='mysql-bin.000001', master_log_pos=75757; - 开启 slave 模式,
start slave - 查看 slave 状态,
show slave status \G,只要看到 IO 和 SQL 线程在允许中,就表明已经在正常工作了。如果后面 Slave 有任何异常行为,都可以通过这个命令检查错误日志。现在,对主库的任何操作都会自动同步到 Slave 中了。1
2
3
4
5
6
7
8
9
10
11
12
13
14*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.19.100
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 75757
Relay_Log_File: slavehost-relay-bin.000005
Relay_Log_Pos: 2997
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
.........
总结
- 进行主从配置,主库和从库需要各自分配不同的 server-id
- 主库还需要开启 log-bin
- 主库需要创建一个用户给从库使用
- Slave 连接主库需要参照主库的日志状态
- 如果 Slave 出现异常,可以先停止服务,然后使用
set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;跳过命令。
Sharding-JDBC 实现读写分离
通过 Sharding-JDBC,我们只需要三配置就能实现 Mysql 读写分离:
- 添加依赖
1
2
3
4
5<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency> - 修改程序的配置文件,删除数据源配置,使用 Sharding-JDBC的数据源
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# sharding配置主从数据库
spring:
shardingsphere:
datasource:
names:
master,slave
# master
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.19.100:3306/dollar_takeout?useSSL=false
username: root
password: root
# slave
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.19.101:3306/dollar_takeout?useSSL=false
username: root
password: root
masterslave:
# 负载均衡算法
load-balance-algorithm-type: round_robin # 轮询
# 最终数据源的名称
name: datasource
master-data-source-name: master
slave-data-source-names: slave
props:
sql:
show: true # show sql on terminal - 允许 bean 覆盖(ShardingJDBC 和 druid 连接池都会创建一个数据源,为了避免冲突,我们要打开 bean 覆盖开关)然后我们就可以启动项目,测试我们的主从分离啦。附上导出导入数据库的命令:
1
2
3spring:
main:
allow-bean-definition-overriding: true # 允许 bean 覆盖
- 导出数据库,
mysqldump -uroot -proot --database ${db.name} --result-file=D:\xxx.sql。--database参数可以同时生成创建数据库的命令,--result-file=可以避免在 Windows 中导出数据库导致的中文乱码问题。 - 导出数据库,
./mysql -h 192.168.19.100 -p3306 -uroot -proot < dt.sql,在 cmd 中执行。这种方式导入上面的 sql 文件,可以直接创建数据库。 - 导入数据库,
source ${path}这种方式需要提前创建数据库,并选中该数据库。
Mysql 实现读写分离
https://travelerentity.github.io/2023/Mysql-实现读写分离/